Kaggle Advent Calender2020の 11日目の記事です。
昨日はhmdhmdさんのこちらの記事です! 2020年、最もお世話になった解法を紹介します - Qiita
明日はarutema47さんの記事です! (後ほどリンクはります)
本記事では、深層学習プロジェクトで使用すると便利なライブラリ、
Pytorch-lightningとHydraとwandb(Weights&Biases)について紹介したいと思います。

対象読者
- Pytorchのボイラープレートコードを減らせないか考えている
- 下記ライブラリについては聞いたことあるけど、試すのは億劫でやってない
書いてあること
- 各ライブラリの役割と簡単な使い方
- 各ライブラリを組み合わせて使う方法
- 各ライブラリのリファレンスのどこを読めばよいか、更に勉強するにはどうすればよいか
また、上記3つのライブラリを使用したレポジトリを用意しました。 ブログと一緒に見ていただくとわかりやすいかと思います! github.com
はじめに各ライブラリを個別に解説し、次に上記レポジトリに注釈を入れながら説明したいと思います。
Pytorch-lightning
概要
Pytorch-lightningはPytorchの軽量ラッパーです。 ボイラープレートコードを排除しつつ、可読性を向上させることが出来ます。
特徴(Lightning Philosophy)
公式GitHubを見ると以下の原則を念頭に置いて設計されているようです。
- 最大限の柔軟性を持てる
- ボイラープレートコードを抽象化しつつ、必要があればアクセスできる
- システムに必要なものをすべてを保持し、自己完結できる
- 以下の4要素に分割し、整理する
- 研究コード(Lightning Module)
- エンジニアリングコード(Trainer)
- 非必須の研究コード(Callback)
- データ (Pytorch DataloaderかLightningDataModule)
どのようなモデルを実装しても似たインターフェースになり、他人(≒過去の自分)のコードでもすぐに理解できる。 MultiGPUやTPUでも実装の変更が殆どないといった点が素晴らしいと思います。
Install
pip install pytorch-lightning
使い方
上記Lightning Philosophyにあるように、4つのパートについてそれぞれ説明していきます。
Trainer
Trainerは後述するLightningModule, Callbacks, DataModuleを引数にとり、Training loop を司るクラスです。いわゆる親玉。
CPU・MultiGPU・TPUなどの実行環境や、デバックモードやエポック数など、
細かい設定を引数に取ることが出来ます。
例)
# 関数にconfig(cfg)を渡すデコレータ(後述) @hydra.main(config_path='../config', config_name='pix2pix') def main(cfg): # モデルの動的呼び出し model = hydra.utils.instantiate(cfg.model.instance,hparams=hparams, cfg=cfg) dm = DataModule(cfg) dm.setup() trainer = pl.Trainer( logger = wandb_logger, checkpoint_callback=model_checkpoint, callbacks=[lr_logger,early_stopping,wandb_callback], **cfg.trainer.args, ) # 学習開始 trainer.fit(model, dm)
どのような引数を取ることができるかは下記リファレンスに記載されています。
trainer - PyTorch Lightning 1.0.8 documentation
LightningModule
参考: LightningModule - PyTorch Lightning 1.0.8 documentation
モデルの学習に関するデータフローなどを記載するクラス。
親クラスにtorch.nn.Module を継承しており、高機能な nn.Module と捉えるとわかりやすいです。
各フェーズごとにメソッドが定義されており、その中に処理を書くことで実行されます。
また、Trainerにわたすことで実行環境に応じたコードを自動で実行してくれます。
つまり、x.cuda() や x.to(device) を呼び出したり、
Dataloader に DistributedSampler(data) を渡す必要がなくなります。
生えてるメソッドの説明
forward
nn.Moduleと同じXX_step
引数batchにdataloaderの中身が格納されているので、 これをモデルに通して、誤差を計算します。 Loggerやtqdm barに渡したい値はself.logに渡すことで記録されます。XX_epoch_end
epochが終わったときにどんな処理を行うかを書きます。 epoch間のlossやmetricの平均値などを記録すると良いと思います。configure_optimizers
optimizer,schedulerの初期化をします。
例)
import os import torch from torch import nn import torch.nn.functional as F from torchvision.datasets import MNIST from torch.utils.data import DataLoader, random_split from torchvision import transforms import pytorch_lightning as pl class LitAutoEncoder(pl.LightningModule): def __init__(self): super().__init__() self.encoder = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 3)) self.decoder = nn.Sequential(nn.Linear(3, 128), nn.ReLU(), nn.Linear(128, 28 * 28)) def forward(self, x): # in lightning, forward defines the prediction/inference actions embedding = self.encoder(x) return embedding # dataloaderの返り値, indexが格納されている def training_step(self, batch, batch_idx): # training_step defined the train loop. It is independent of forward x, y = batch x = x.view(x.size(0), -1) z = self.encoder(x) x_hat = self.decoder(z) loss = F.mse_loss(x_hat, x) # 追跡したい値はself.log取ることができる self.log('train_loss', loss) return loss def configure_optimizers(self): optimizer = torch.optim.Adam(self.parameters(), lr=1e-3) return optimizer
Callbacks
参考:Lightning in 2 steps - PyTorch Lightning 1.0.8 documentation
学習に非必須な処理を書くクラス。
Logger , EarlyStopping LearningRateScheduler など。
一般的によく使われる処理はすでに用意されています。
自分で書く場合は、LightningModuleと同じメソッドが生えているので、
各フェーズで何をするかを書きます。
こちらもTrainerに引数として渡します。
例)
class DecayLearningRate(pl.Callback) def __init__(self): self.old_lrs = [] def on_train_start(self, trainer, pl_module): # track the initial learning rates for opt_idx in optimizer in enumerate(trainer.optimizers): group = [] for param_group in optimizer.param_groups: group.append(param_group['lr']) self.old_lrs.append(group) def on_train_epoch_end(self, trainer, pl_module, outputs): for opt_idx in optimizer in enumerate(trainer.optimizers): old_lr_group = self.old_lrs[opt_idx] new_lr_group = [] for p_idx, param_group in enumerate(optimizer.param_groups): old_lr = old_lr_group[p_idx] new_lr = old_lr * 0.98 new_lr_group.append(new_lr) param_group['lr'] = new_lr self.old_lrs[opt_idx] = new_lr_group
DataModule
データにまつわる全てのコードを集約するためのクラスです。
DatasetとDataLoaderの呼び出しをします。
(Pytorch-lightning 1.0以前はデータにまつわる処理も LightningModule に書く必要がありました。)
例)
class MyDataModule(LightningDataModule): def __init__(self): super().__init__() def prepare_data(self): # download, split, etc... # only called on 1 GPU/TPU in distributed def setup(self): # make assignments here (val/train/test split) # called on every process in DDP def train_dataloader(self): train_split = Dataset(...) return DataLoader(train_split) def val_dataloader(self): val_split = Dataset(...) return DataLoader(val_split) def test_dataloader(self): test_split = Dataset(...) return DataLoader(test_split)
pytorch-lightning.readthedocs.io
Hydra
概要
Facebook Open Sourceから公開されている設定管理ツールです。 YAMLやDataclassから設定変数を階層構造をもたせて動的に呼び出すことができます。
特徴
- 複数のソースから階層的に設定を構築できる
- コマンドラインから設定の指定や上書きが可能
- 1つのコマンドで複数のジョブを実行できる
Install
pip install hydra-core --upgrade
使い方
最小限の使い方
configファイルにyaml形式で設定を書きます。
# config.yaml db: driver: mysql user: omry pass: secret
参考:YAML Syntax - Ansible Documentation
設定を呼び出す側には呼び出したい関数に @hydra.main デコレータを渡します。
各要素にはドットノーテーションでアクセスできます。
# main.py @hydra.main(config_path="./config",config_name="config") def my_app(cfg : DictConfig) -> None: print(cfg) print(cfg.db.driver)
Config の構造化
configディレクトリを階層構造にすることで、configも階層構造でもたせる事が可能になります。 例えば、以下のようにディレクトリを構築します。
config
├── config.yaml
├── data
│ ├── cifar10.yaml
│ └── mnist.yaml
└── model
├── resnet_18.yaml
└── resnet_50.yaml
そしてrootとなる config.yaml を下記のように記載すると、
data, modelそれぞれ指定したyamlファイルを読み込んでくれます。
# config.yaml
defaults:
- data: cifar10
- model: resnet_18
呼び出される側の設定ファイルの1行目に # @package _group_ と記載すると、
そのディレクトリ名経由でドットノーテーションアクセスできます。
# @package _group_ shape: [1,28,28] batch_size: 8
を ./config/data/default_data.yaml に書いたなら、cfg.data.shape とアクセスできます。
非常に便利な機能ですが、どの単位でフォルダを分割するかが結構難しいです...!
良いアイディアがあったら教えてほしいです🙇
コマンドラインでの上書き
コマンドライン引数にわたすことで呼び出すファイルや設定を上書きできます。
# 設定ファイルの入れ替え
python train.py data=cifar10
# 値の変更 python train.py trainer.min_epoch=100
インスタンスの動的呼び出し
参考: Instantiating objects with Hydra | Hydra
Hydraの強力な機能にオブジェクトの動的呼び出しがあります。
_target_ に呼び出したいオブジェクトを指定し、引数を列挙することで動的に呼び出すことが出来ます。
# ./config/callbacks/default_callbacks.yaml # @package _group_ EarlyStopping: # 呼び出したいオブジェクト名 _target_: pytorch_lightning.callbacks.EarlyStopping # 第2要素以降はオブジェクトの引数 monitor: ${trainer.metric} mode: ${trainer.mode}
# 呼び出し側。コード内のローカル変数を引数にしたい場合はキーワード引数で渡す。
model_checkpoint = instantiate(cfg.callbacks.ModelCheckpoint,patience=patience)
ユニットテストやnotebookで呼び出す方法
initialize_config_dir メソッドを使うことで呼び出すことが出来ます。
from hydra.experimental import initialize_config_dir, compose with initialize_config_dir(config_dir=config_dir): cfg = compose(config_name=config_name)
Wandb
概要
Wandbは機械学習プロジェクトの実験のトラッキング、ハイパーパラメータの最適化、
モデルやデータのバージョンニングを行うライブラリです。
install・会員登録
pip install wandb
公式サイトの右上のLoginリンクからsign upすれば使えます。
GithubかGoogleアカウントを連携すればOKです。
Weights & Biases - Developer tools for ML
特徴
大きく分けて下記の機能があるようです。 (自分はまだDashboardくらいしか使っておりません🙇)
- Dashboard: 数行のコード追加で実験logを記録
- Sweeps: 複数の条件のモデルを一度に実行
- Artifacts: モデルやデータなどをバージョンニングフォルダのように管理
- Reports: 自分の実験を他者に見やすく公開
複数のPCの実験結果をWebブラウザから一括で見られるのは非常に便利だと感じました。
使い方
最小限の使い方
主にPytorch-lightningで使用する方法について説明します。
参考: PyTorch LightningとWandbの連動方法
使い方は非常に簡単で、 pytorch_lightning.loggers.WandbLogger を呼び出して、Trainer に渡すだけです。
tagsやnameを指定すると、project内の実験をソートしたり条件を絞るのに便利。
from pytorch_lightning.loggers import WandbLogger wandb_logger = WandbLogger( name="ResNet18-cifar10", project=”ImageCrassfication”, tags=["ResNet18","cifar10"]) trainer = pl.Trainer(logger=wandb_logger,**trainer.args)
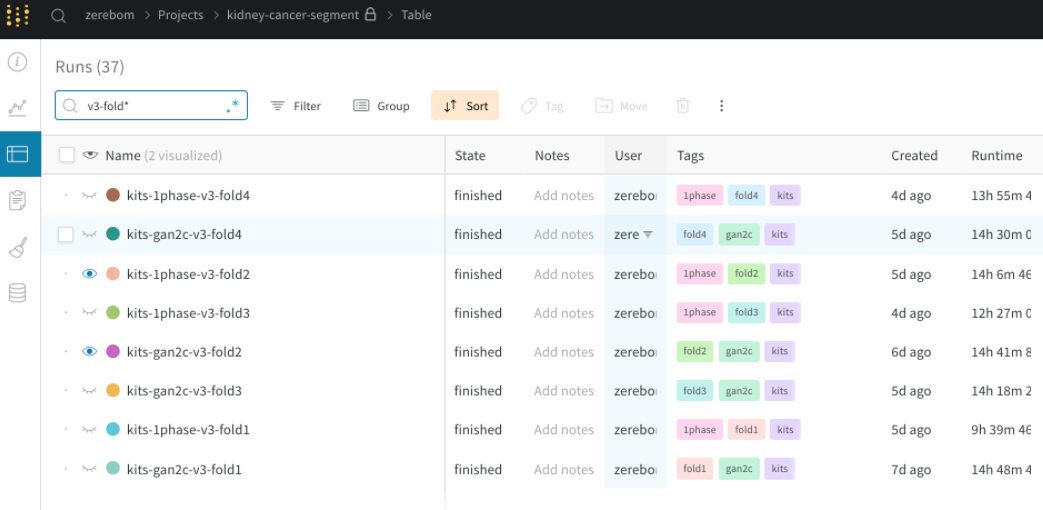
Traceしたい値は、LightningModuleで self.log に指定するだけで自動で追加してくれます。
def training_step(self, batch, batch_idx): loss, k_dice, c_dice = self.calc_loss_and_dice(batch) self.log("k_dice", k_dice) self.log("c_dice", c_dice) return loss
さらに、 watch メソッドを呼ぶだけで、モデルの重みの分布を記録してくれます。
wandb_logger.watch(model, log='gradients', log_freq=100)

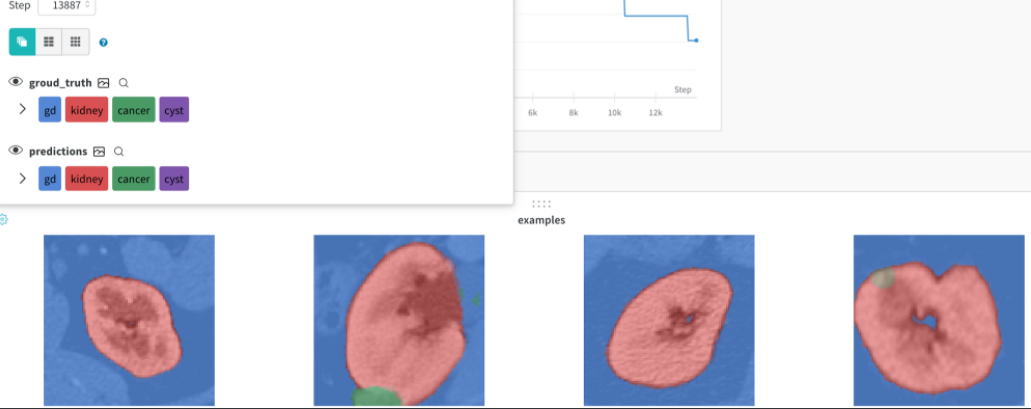
画像の出力
GANのGeneratorの生成結果や、Segmentの結果などを出力する機能もあります。
Pytorch-lightningで使用するには Callback を書き、Trainerに渡すことで保存できます。
class ImageSegmentationLogger(Callback): def __init__(self, val_samples, num_samples=8,log_interval=5): super().__init__() self.num_samples = num_samples self.val_imgs, self.val_labels = val_samples self.log_interval = log_interval def on_validation_epoch_end(self, trainer, pl_module): # Bring the tensors to CPU val_imgs = self.val_imgs.to(device=pl_module.device) val_labels = self.val_labels.to(device=pl_module.device) #[B,C,Z,Y,X] pred_probs = pl_module(val_imgs) #[B,Z,Y,X] -> [B,Y,X] preds = torch.argmax(pred_probs, 1)[:,0,...].cpu().numpy() val_labels =torch.argmax(val_labels, 1) [:,0,...].cpu().numpy() class_labels = { 0: "gd", 1: "kidney", 2: "cancer", 3: "cyst" } # Log the images as wandb Image trainer.logger.experiment.log({ "examples": [wandb.Image(x, masks={ "predictions": { "mask_data": pred, "class_labels": class_labels }, "groud_truth": { "mask_data": y, "class_labels": class_labels } }) for x, pred, y in zip(val_imgs[:self.num_samples], preds[:self.num_samples], val_labels[:self.num_samples])] })
サンプルレポジトリの解説
GitHub - zerebom/hydra-pl-wandb-sample-project
config dir
実験パラメータは ./config/default_config.yamlを通して渡されます。
├── config │ ├── callbacks │ │ └── default_callbacks.yaml │ ├── data │ │ └── default_data.yaml │ ├── default_config.yaml │ ├── env │ │ └── default_env.yaml │ ├── logger │ │ └── wandb_logger.yaml │ ├── model │ │ └── autoencoder.yaml │ └── trainer │ └── default_trainer.yaml
train.py
実行する train.py は基本的にpl.Trainerの組み立てだけ行います。
@hydra.main(config_path='../config', config_name='default_config') def train(cfg: DictConfig) -> None: model = instantiate(cfg.model.instance,cfg=cfg) dm = DataModule(cfg.data) dm.setup() wandb_logger = instantiate(cfg.logger) wandb_logger.watch(model, log='gradients', log_freq=100) early_stopping = instantiate(cfg.callbacks.EarlyStopping) model_checkpoint = instantiate(cfg.callbacks.ModelCheckpoint) wandb_image_logger = instantiate(cfg.callbacks.WandbImageLogger, val_imgs=next(iter(dm.val_dataloader()))[0]) trainer = pl.Trainer( logger = wandb_logger, checkpoint_callback = model_checkpoint, callbacks=[early_stopping,wandb_image_logger], **cfg.trainer.args, ) trainer.fit(model, dm)
それぞれのパーツは ./src/factory dirに入っています。
└── src
├── factory
│ ├── dataset.py
│ ├── logger.py
│ └── networks
│ └── autoencoder.py
output dir
poetry run python train.py を実行すると、output dirが作成されます。
ここに重みやlogが格納されます。
output
└── sample-project
└── simple-auto-encoder-1
output dir の出力先は default_config.yaml で設定できます。
hydra:
run:
dir: ${env.save_dir}
# env.save_dir: ${env.root_dir}/output/${project}/${name}-${version}
おわりに
ここまで読んでいただきありがとうございます!
(スコープを広げすぎてとっ散らかってしまった気がする...)
実験管理ディレクトリの作成はなかなか奥が深く、人によって個性が出ると思います。
exp dirを作って1実験1ファイルで管理する方法も人気が高いみたいですね。今度そのような方法にも挑戦してみたいです。
今後、もっと複雑なGANモデルを実装して公開したいと思ってます。
(このGANを書き直す予定)
lucidrains/lightweight-gan
参考文献
レポジトリ
wandb+Hydraを使用したKaggle solution
非常に参考にさせていただきました🙇
shimacos37/kaggle-trends-3rd-place-solutionpytorch-lightning公式 Template
PyTorchLightning/deep-learning-project-template
Pytorch-lightning
pytorch-lightningでCycleGAN実装例
GANはLightningModuleにモデルが2つ以上必要になるので、ちょっと書き方にコツが要ります。
CycleGAN - Pytorch LightningPytorch-lightning 日本語解説
PyTorch Lightning入門から実践まで -自前データセットで学習し画像分類モデルを生成-
Hydra
Hydra + Mlflow
ハイパラ管理のすすめ -ハイパーパラメータをHydra+MLflowで管理しよう- - やむやむもやむなしHydra + Ax
Hydraでハイパーパラメータのサーチができるそうです
【Zoom or Die】第2回 Hydra+Axでハイパーパラメータサーチ - Sansan Builders Blog
Wandb
wandb Gallery
WandbのReport機能を使って公開された実験のギャラリー
The Gallery by Weights & Biasespytorch-lightning with wandb
上のGalleryの中でPytorch-lightningを一緒に使っているライブラリ
PyTorch Lightning