RankNetとLambdaRankの解説
本記事はWantedly 21新卒 Advent Calendar 2021の22(???)日目の記事です!(今は2021年12月22日 午後220時です。)
最近、From RankNet to LambdaRank to LambdaMART: An Overview というサーベイ論文を読みました。本記事ではその論文をもとに、ランキング学習のアルゴリズムである、RankNet, LambdaRankの解説をしたいと思います。
なるべく数式を噛み砕いて説明しようと思いますが、久しぶりにちゃんと数式を追ったので、間違っている部分もあるかもしれないです...悪しからず...(数式はサーベイ論文から引用しています。)
ランキングモデル・ランキング学習とは?
ランキングモデルとは、アイテムの集合を、定義した重要度順にソートして返すモデルのことを指します。このモデルを機械学習を使って構築すること、そのスキームを、ランキング学習(Learnig To Rank, LTR)と呼びます。
ランキングモデルは入力に、何ついて情報を得たいか指定する”クエリ”とアイテムの特徴量を受け取り、重要度順にソートされたアイテム群や、アイテム群の重要度のスコアを出力します。LTRの文脈では各アイテムのことを文書(docment)と呼ぶことが多いです。

RankNetとは
RankNetはデータセット内のクエリが同じアイテムをランダムに2つ選び、そのペアの順序関係が正しくなるように学習を進める、Pairwiseランキング学習の手法の一つです。
RankNetのベースモデルは、アイテムの特徴ベクトルを入力に、重要度のスコアを出力します。
このベースモデルから得られる、二つのアイテムSi, Sj のスコア差をsigmoid関数に通すことで、アイテム Si > Sjとなる確率を求めます。
そして、この Si > Sjとなる確率と理想的な並びになるとき得られる真の確率に近づけるように学習をします。
真の確率との誤差はクロスエントロピーで計算します。

理想の確率は以下の通りです。
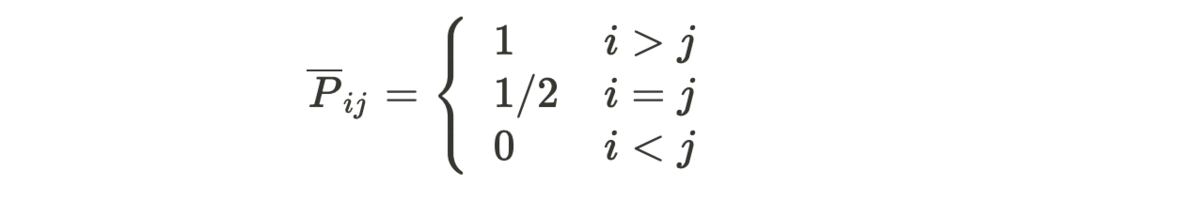
モデルパラメータwの更新に必要な損失Cの微分は以下のようになります。
数式メモ
- wがi, jの合成関数なので、項が二つに別れる
なので、不等号を入れ替えて項をまとめている
このλは、アイテムiがアイテムjから受ける勾配として捉えることができます。
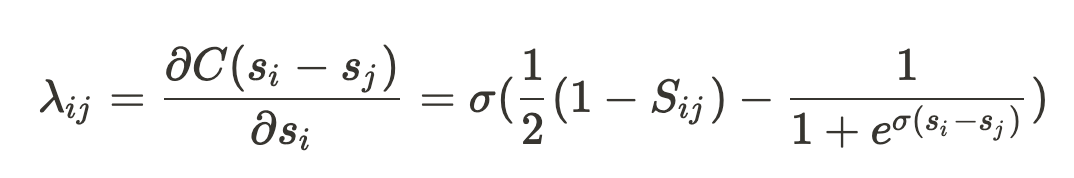
数式メモ
だと値は0に、
だと -2σに近づく
- 順序関係が誤っている場合は、負の方向にスコアが更新される
LambdaRankとは
LambdaRankは以下のようなRankNetの課題を解決するために改良したランキングモデルです。
- RankNetが行うのは、あくまでペア同士の順序関係の最適化なので、アイテムの位置によって損失への重みを変えることができない
- 一般的にランキングは上位アイテムの並び順に強い重みをつけたほうが良い
- nDCGやMRRなどランキングの評価指標も上位アイテムの並び順に強い重みをつけている
- 1回のモデルの更新のために、全アイテムの組み合わせのスコア差が必要で、計算量が多い
- 例えばiの勾配を得るには、i以外全てのアイテムとのスコア差を算出する必要がある。
上記の問題を解決するために、LambdaRankは勾配として利用するλを以下のように定義します。
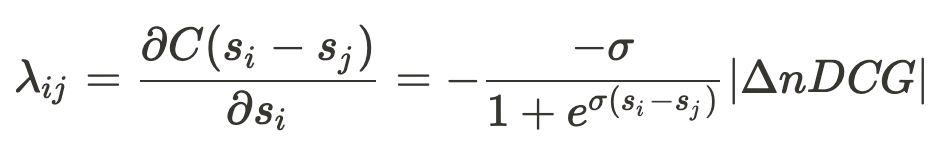
この はi, jを入れ替えた時のnDCGの差分で、またnDCGに限らず、任意のランキングの評価指標に置き換えて学習することもできます。
なぜ置き換えが成立するのかというと、アイテムを入れ替えた時のランキングの評価指標の差分もRankNetの の項と同様に、スコアの出力が真の確率から遠いほど、大きな負の値をとるという性質を持っているからと、解釈しています。
この置き換えを行うことで、モデルを1回更新するのに、必要な計算量が減り、また任意の評価関数を可能になります。つまりRankNetの課題を解決することができます。
おわりに
久しぶりに数式をちゃんと追って論文を読みました。めちゃくちゃ時間かかるけど、さっと読んでもすぐ忘れてしまうので、たまにはじっくり読むの良いなと思いました💪 サーベイ論文で紹介されていたLambdaMARTについても、いつかちゃんと読み込んでブログに足していきたいです...!(一応読んだけど、人に説明できるほど理解できなかったorz)
余談ですが、Wantedly 21新卒 Advent Calendar 2021 を無事走破できました!🎉 他の記事も良ければ読んでみてください!
zerebom.hatenablog.com www.wantedly.com zerebom.hatenablog.com zerebom.hatenablog.com
参考文献
ランキング学習の概要 jp.kamulau.com
RankNetの実装 www.szdrblog.info
RankNetの実装 qiita.com
RankNetの解説 ryo59.github.io
LambdaNetの解説 jp.kamulau.com
LambdaMartの解説 jp.kamulau.com
新卒で読んだ技術書・ビジネス書8選
こんにちは、Wantedlyでデータサイエンティストをしている21新卒の樋口です。
本記事はWantedly 21新卒 Advent Calendar 2021の18日目の記事です!
この記事では入社後に読んで、実務で役に立った本を紹介したいと思います。 中身を忘れてしまった本もあったので、いい機会と思って読み返し、それぞれ面白かったポイントを3つピックアップしました。
これまで読んだ本たち

技術書
達人に学ぶSQL徹底指南書 第2版
概要
SQLの正しい書き方・考え方を紹介した本。前半はモダンなSQL機能を駆使したクエリの書き方、後半はリレーショナルデータベースの開発の歴史から、SQL を作った人が何を考えて現在の形にしたのかというバックグラウンドについて書かれている。
ポイント
- CASEは文ではなく式。必ず値を返すため、列名や定数をかける場所、全てに用いることができる
- (
SELECT, WHERE, ORDER BY, HAVING, PARTION BY, etc.)
- (
- EXISTは行の集合を入力とする述語(= 真理値を返す関数)。「全てのxが条件Pを満たす」、「条件Pを満たすxが存在する」といった文を書くための量化子として用いることができる
- HAVINGは集合に対する検索を行う句。CASEと組み合わせることで、柔軟に集合をフィルタリングできる
- ex)
having count(*) * 0.75 = sum(case when score >=80 then 1 else 0 end) -- 75%以上の生徒が80点以上をとったクラスの抽出
- ex)
感想
SQLは自由度が高く、体系だった知識を身につけないと可読性の悪いクエリを書き続けてしまうと感じたので読みました。自分のニーズにぴったりで、集合論や述語論理を交えて式や文が紹介されており、読む前よりどういう時にどんな構文を利用すれば良いか、区別をつけられるようになりました。演習問題もついているので、しっかり身につくと思います😎
施策デザインのための機械学習入門
概要
機械学習を使ってビジネス上に有益な変化をもたらすには、どんなことに気をつけ、対策する必要があるか紹介した本。”広告画像のパーソナライズ"や、”implicit feedbackを用いたランキングシステムの構築”など実践的な例を使って、解くべき問題を定め方や、学習データと実世界のデータの乖離を定式化、モデルへの反映方法などを紹介している。
ポイント
- 機械学習実践のためのフレームワークには以下のステップが存在する
- KPIの設定 → データの観測構造のモデル化 → 解くべき問題の特定 → 観測データのみを用いて解く方法を考える → MLモデルの学習 → 施策の導入
- 手元にあるデータの最適化が、真の目的関数の最適化と近似できるのか意識する
- Implicit feedbackを使ったランキングモデルにおいて、ナイーブにログデータに対して最適化を行うと、上位ポジションのアイテムが過大評価され、バイアスを強めるループを生んでしまう
感想
学生時代に取り組んでいた研究や、データ分析コンペでは、手元にあるデータを使って、モデルの損失関数を最小化することがそのまま、真の目的関数の最適化をすることと等しいケースが殆どでした。一方で会社に入ってから取り組んだ施策においては、そもそも”どんな指標を最適化するべきか”から決める必要があったり、学習データとテストデータに大きな乖離があったりで非常に苦戦しました。。。
この本は機械学習モデルを精度良く学習させるためのノウハウではなく、機械学習を使って、ビジネス上で有益な変化をもたらせるに必要な前段階に焦点を当てており、上記のような、実務で改めて考える必要が生まれた領域に対して非常に参考になりました。
ロジカルシンキング系
自分のアタマで考えよう
概要
ちきりんさんがブログを書くにあたって、日常的に使っている「思考のワザ」を紹介した本。 情報を与えられた時、いかに洞察を得て、有用なアウトプットを出すにはどうすれば良いか、彼女自身の思考のワザの使用例を交えながら説明している。
ポイント
- 知識は過去に他の人が、その人の頭で考えたこと。「自分の頭で考える」とは知識と自分の思考を切り分けることから始まる
- 「考える」とは情報→結論に変換するプロセス。仕事中に結論を出さず、単に情報収集に終始してないか自覚しよう
- 全ての分析の基本は比較から始まる。縦(=時系列)の比較、横(=他者)の比較の2軸で行おう
感想
働いてから自分は、受験勉強のような知識を詰め込む行為は慣れているけど、自分で考えて結論を出すのはかなり苦手(=避けてきた)だと自覚しました。また、考える力をつけるには、自分がどれくらい考えることに時間を使っているか自覚すること。そして、その時間を増やすことが必要と書いてあり、ハッとしました。
時折読み返して、自分の頭で考えることの大切さを忘れないようにしたいです。また、本を端から舐めて読んだり、コードを手ぐせで書き始めるような思考停止な行動は減らしていきたいです。
論点思考
概要
経営における最も重要な過ちは、間違った答えを出すことではなく、間違った問いに答えること。 解くべき問題「論点」を定義するプロセス「論点思考」の重要性や鍛え方を紹介した本。
ポイント
- 4つのステップを経て、論点を確定してから分析や作業に取り掛かろう
- 論点候補を拾い出す→論点を絞り込む→論点を確定する→全体像で確認する
- 論点と現象を見極めることで、打ち手を狭めよう
- 現象: 会社に泥棒が入った → (無数の打ち手)
- 論点1: 防犯体制に不備がある → 防犯体制を整える
- 論点2: 会社の評判が落ちた → イメージ向上の必要性検討
- 論点思考力を高めるには「本当の問題は何か常に考える」、「視野・視座・視点"を変えて考える」ことが必要
- 視野: 普段あまり見ていない方向に眼を向ける
- 視座: 2つ上のポジションに付いたつもりで仕事する
- 視点: 切り口を変えてみる(etc. 業界最下位だとしたら?、自分が顧客だったら?)
感想
与えられたタスクの意図を読み違えたり、ズレたことを考えてしまい出戻りが起きてしまうことがあったので読みました。 ここに書かれていること全部を意識して業務を進めるのはすぐには難しいかもしれないですが、まずはタスクの意図はなんなのか? 何を目的としているのか?から考えて作業に取り組む癖をつけたいです。
文章
コミュニケーション技術 - 実用的文章の書き方
概要
自分の考え、意見、経験を表す情報を提示し、読み手に行動を求める「実用文」の書き方を紹介した本。読みやすい文章にするワンポイントアドバイスと、身近な実用文(ex. 家電の説明書, 会議の議事録)にアドバイスを適応した添削例が交互に書かれている。
ポイント
- 単語の選び方: 事実を正確に伝えられるように、どのようにも解釈できる単語の使用は控えよう
- 曖昧な動詞を避ける: 見る→点検する, 試験する, 動かす→ 位置を変える, 運転する
- 曖昧な形容詞を避ける(良く, 大幅に, 十分に → xx%)
- 明瞭な文の作り方: ひとつの文が一つのまとまった考えを表現しよう
- 受動態を多用しない: 動作主が曖昧になり文が長くなる
- パラレリズムの原則を活用する: 複数文を羅列するとき、各文の構成(ex. 原因→結果)を揃えると読みやすい
- パラグラフのまとめ方: 総論→各論の順で展開しよう
- 総論のポイント
- ×「市内に高速道路を作ることは論議に値する問題である」
- ◯「高速道路は景観を損なうので、住民の多くは反対している」
- 総論のポイント
感想
文章の構成に関する章も面白かったですが、どんな動詞・名詞・形容詞を使えばよいか、のようなミクロなアドバイスが日々の実務で取り入れやすかったです。
理工系のための良い文章の書き方
概要
学生・新入社員向けに、より良い文章を自力で書けるようになるための原則・コツ・ヒントを紹介した本。
ポイント
- 文章を書く前に伝えるべきことをまとめた(主題文)を最初に書こう
- 大事なことから書こう
- 読み手が驚かない文章構成にしよう(既知の情報→未知の情報と繋げる, 読み手が予測しやすい文章にする)
感想
"コミュニケーション技術 - 実用的文章の書き方”にもあった通り 、ビジネス上の文章は読み手に情報を伝えることが責務です。読み手が何を知りたいかを考えることが、何より重要だと改めて認識できました。
自己啓発系
ドラッカー・スクールのセルフマネジメント教室
概要
VUCA(変動/不確実/複雑/曖昧)な世の中で、自分の望みの結果を得るために、思考・行動に自覚的(=マインドフルネス)になる方法を紹介した本。なぜ人は無意識に望んでいない結果を得てしまうのか、どんな思考の癖をつければ望みの結果を得られるかなども解説してる。
ポイント
- 人は今この瞬間の行動を選ぶことしかできない。ので、未来や過去に悩み続けず、今何を望んでいるか、どんな選択肢があるかに目を向けよう
- 頑張っているのに、結果が出ない人はそもそも自分がどんな結果を望んでいるのか自覚していない
- 人は脳のリソースを節約するために、日常で多くの行動を無意識に選んでいる。望んでいない結果は、どんな無意識の選択からもたらされてるか意識することで、得られる結果を変えられる
感想
自分は周りの評価を気にしてしまう性格なので、結果が求められる・評価される社会人という立場は思ったより、メンタルに負荷がかかるなと気づきました。適度なストレスはパフォーマンスを高めると書いてありましたし、そのような環境をむしろ味方につけて、パフォーマンスを発揮できるようにマインドフルネスを獲得していきたいです。今回紹介した本の中で一番読み返してます。
漫画 君たちはどう生きるか
概要
人間としてあるべき姿を求める、コペル君とおじさんの物語。二人の対話とノートを通じて、どう生きるかについて指針を与えてくれる本。
ポイント
- 人間は道義に外れたことをすると、辛いという感情が芽生える。この性質があるから自己を顧みて、より良い自分になれる
- 悔恨の想いにうたれるのは自分がそうでない行動をすることができたから。この想いに苦しむのは正しい道に向かおうとしているから
- 世の中は太陽のような1つの大きな存在が動かしているのではなく、誰かのためにという一人一人の思いが動かしている
感想
社会人になってから、人生における仕事の比重の大きさ、想像以上の日々の忙しさを実感しました。同時に、どんな仕事をし、どうやって生きるかを考えないとあっという間に歳だけとってしまうなと思って読みました(真面目か)。迷いながらも、どう生きるかを深く考えること事態が、人生を良くしていく。自分の意識で自分の行動は変えられるといった、おじさんのアドバイスに勇気づけられました。
おわりに
読んだ本をまとめると、たくさんの本を読んでるけど、かなりの部分覚えていないし、何割を日々の仕事に活かせているだろうか...と気付かされました。。。中身を思い出すためにもこんな形で、定期的におすすめ本の紹介をやってもいいのかも!と思いました。
本を読むことで得られる、なんかやった感が目的で読んでいる部分もあったなと思います。知識を得たとしても、日々実践できる量は限られてますし、今後は読むペースを落としてでも1冊への理解を深めたり、読了後どう日々に生かすのかと考えることに重きを置きたいなと思いました〜。
【GPT-3 × streamlit】ブログの”タイトル・本文を自動生成するサイトを作った話

はじめに
こんにちは、Wantedlyでデータサイエンティストをしている21新卒の樋口です。
本記事はWantedly 21新卒 Advent Calendar 2021の7日目の記事です!
今日、この記事では.....................!
.....
.....
.....
何を書こう....

アドベントカレンダーを5人で制覇するぞ!と言っておきながら、2記事目でネタがなくなってしまいました。ブログ書くぞ!と意気込んだものの、なかなかネタが降りてこない時ってありますよね🥲
そんな問題に解決できるように、ブログの”タイトル・本文を自動生成するサイトを作りました!
その名もブログネタだし君です!!
ブログネタだし君はブログのタイトルと本文を生成してくれるWebアプリです。 "プロンプト"と呼ばれるお題と例示を与えると、その情報から何を答えるべきかを理解して、回答してくれます。
デモ
タイトルの生成
まずはアドカレの"タイトル"のアイディアを授かりましょう。 自分のブログのタイトルを例示し、"データサイエンティストのブログのタイトル”を出力させます。

そして待つこと数秒....タイトル案を出してくれます!

何だか良さそうなタイトルを出してくれました! (二つ目のタイトルはかなりディープラーニングディープラーニングしていますが。)
動画だとこんな感じです。(確率的に結果を返すので上の例と出力が違います) youtu.be
記事本文の生成
次は先ほど生成してくれたタイトル「【最新情報】TensorFlow Liteが正式リリースされました! 」の中身を書いてもらいましょう。 自分のブログのタイトルと書き出しを例示して、生成してみます。

そして待つこと数秒....本文を生成してくれます!
タイトル: 【最新情報】TensorFlow Liteが正式リリースされました! 本文: こんにちは、21新卒の樋口です。本日はWantedly Advent Calendarの2日目です! 先日Google I/OでTensorFlow Liteが正式にリリースされました! TensorFlow Liteはモバイル向けの深層学習ライブラリで、ソフトウェアの実行時間を短縮してメモリ使用量を削減することができます。 TensorFlow Liteの使い方については以下の記事が参考になります。https://www.tensorflow.org/lite/tutorials また、TensorFlow Liteを使用したモバイルアプリケーションを作成するためのガイドが公開されて
AIが生成した文章とは思えないです。生成結果をさらに例示として与え、続きを書いてもらいましょう!
こんにちは、21新卒の樋口です。本日はWantedly Advent Calendarの2日目です! 先日Google I/OでTensorFlow Liteが正式にリリースされました!TensorFlow Liteはモバイル向けの深層学習ライブラリで、ソフトウェアの実行時間を短縮してメモリ使用量を削減することができます。TensorFlow Liteの使い方については以下の記事が参考になります。https://www.tensorflow.org/lite/tutorialsまた、TensorFlow Liteを使用したモバイルアプリケーションを作成するためのガイドが公開されています。https://developers.google.com/machine-learning/tensorflow/lite/getting-starte レポジトリには、モデルのトレーニングと実行を行うための2つのファイルがあります。tf_lite_model.pyはトレーニングを行うモデルファイルで、モデルの出力を表示するためにprint()メソッドが追加されています。tf_lite_exec.pyは実行するファイルで、モデルを使用して画像の特徴量を計算します。
続きも上手に書いてくれました!これで何記事も量産できそうです😎
ブログネタだし君の作り方
せっかくなのでブログネタだし君の作り方を紹介します。たった70行+αで書けます。
実装はこちら↓ github.com
文章生成エンジンには”OpenAI API", Webアプリのインターフェースは"streamlit"を利用しています。開発に必要な作業は以下の通りです。
- OpenAI APIにユーザ登録する
- API keyを取得する
- API keyを環境変数にセットし、コードを書く
- streamlit runでlocalhostでアプリを起動する or デプロイする
以降、実装に利用したOpneAI APIとstreamlitについて紹介します。
OpenAI API
OpneAI APIとは自然言語・コードの生成と理解を伴うほぼ全てのタスクに適用できるAPIです。タスクに沿ってさまざまなモデルをパラメータを調整して、利用することができます。
The completions endpoint is at the center of our API. It provides a simple text-in, text-out interface to our models that is extremely flexible and powerful. You input some text as a prompt, and the model will generate a text completion that attempts to match whatever context or pattern you gave it. For example, if you give the API the prompt, “As Descartes said, I think, therefore”, it will return the completion “ I am” with high probability.
最近、強力な言語モデル、GPT-3がwaitlistなしで利用できるようになりました。
どんなタスクを解けるのか
大きく分けて、以下のタスクを解くことができます。
- お題と例示を与えると、 続きを補完してくれる
Completion(ブログネタ出し君はこれ) - 文章内の検索をする
Search - 質問回答してくれる
Question ansering
また与えるプロンプトやモデルパラメータを調節することで、さまざまなタスクを解くことができるようになります。
- チャットボット
- SQL生成
- 文書要約
- etc.
利用できるタスクリスト↓

https://beta.openai.com/examples
うまく生成させるには
上手に文章を生成させるには、タスクの複雑さとプロンプトの質にかかっています。目安としては、中学生でも理解できる文章題のように書くといいでしょう。
以下の3つを守ると高品質な生成結果が得られるとのことです。
- 指示、例の二つを組み合わせて何を求めているか明確にする
- 質の高いデータを提供する
- 設定を見直す
- 答えが一意になるものなら、
temperature、top_pを高く、そうでないなら低く設定する
- 答えが一意になるものなら、
また、高品質な例示が多いほど、APIの出力は洗練されていきます。 APIの生成結果で気に入ったものがあれば、例示に加えることでより高品質な生成結果を得られるようになるでしょう。
詳しいtipsはOpenAI APIのdocsに載っています。
streamlit
stereamlitはPython製のWebアプリフレームワークです。フロントエンドの経験を必要とせず、数分で共有可能なアプリを作ることができます。
こちらも最近 version1.0がリリースされました🎉
streamlitの使い方
streamlitは構文が平易かつ、docmentが充実しているので、tutorialとapi referenceを読めば簡単に使いこなせると思います。 自分もブログネタだし君のUIは1時間くらいで作成できました。
おわりに
今回は、正式リリースとなったstreamlit, GPT-3の一般利用が可能になったOpenAI APIの紹介を兼ねて、簡単なアプリを作ってみました。世の中便利なAPI、フレームワークが出てきて、パッとデモを作るのは本当に簡単になったと思います。
また、生成される文章が本当に人間が書いたようなクオリティで驚きました。プロンプトで丁寧に情報を与える必要はありますが、アイディア次第では十分実用可能なものが作れると思います。
ではまた5日後〜、ブログネタだし君を使わなくて済むよう、早めに用意したいです😇
ブログネタだし君の公開について
OpenAI APIは無料で利用枠が限られているため、ブログネタだし君は現在公開していません🙏
openai.com
ただし、GitHubのInstallation通りに実行すればすぐにローカルで立ち上がるようになっています。よければこちらから使ってみてください! github.com
参考記事
せっかくなので言語モデルを使った有名アプリを紹介します。頑張って作り込めばこれくらいのクオリティ・人気のアプリができるかもです...!
Baysian Personalized RankingとMatrix Factorizationの比較(実装編)

こんにちは、Wantedlyでデータサイエンティストをしている21新卒の樋口です。
本記事はWantedly 21新卒 Advent Calendar 2021の2日目の記事です!
5人で25記事書くの半端なく大変ですが、頑張っていきたいです...!
先日Bayesian Personalized Ranking(BPR)という推薦システムの有名な論文(引用数4000程度)を読みました。 [WIP] BPR: Bayesian Personalized Ranking from Implicit Feedback · Issue #51 · zerebom/paper-books · GitHub
アイテムの評価値の予測誤差を最小化するのではなく、評価値の順序を最適化することで、精度高くアイテムを推薦しようという趣旨の論文です。しかし、読んだだけでは本当にうまく行くのか?実装はどうなるのか?と疑問がつきませんでした。
そこでより理解を深めるために、人の実装を参考にしつつ実際にPythonで動かしてみました。本記事では、pytorch-lightingを使った、BPRとMatrixFacotorization(MF)を実装方法と、簡単な評価について紹介します。
(※免責: 本記事は解釈や実装に間違いがあるかもしれないです、ご了承ください🙇)
BPRとMFの簡単な解説
まず今回実装したMFとBPRについて解説します。
Matrix Factorization(MF)
MFは協調フィルタリングの一種です。評価値行列をユーザ・アイテムそれぞれを表す行列に分解したのち、その2つの行列積と元の評価値行列の誤差を小さくすることで、未評価アイテムの評価値を算出します。

2006年にNetflix Prizeの参加者のSimon Funkさんが考案したものが元祖で、行列積の二乗誤差と正則化項の合計を最小化します。
 更新式は以下の通りです。
更新式は以下の通りです。

数式は: Matrix Factorizationとは - Qiita から引用させていただきました🙇♂️
詳しくは下記リンクを参考にしてください。
Baysian Personalized Ranking(BPR)
MFは評価値の誤差の最小化を測る推薦システムです。しかし、以下のように評価値の誤差が小さくなっても実際にアイテムがユーザにとって良い並び順になるとは限りません。 (label 1: 興味あり, 0:なし なので, label 1のアイテムが上位に来てほしい)

そこで、BPRは誤差の最小化ではなく、興味の(ある/ない)アイテムの評価値を大小関係の最適化をします。具体的にはユーザの興味度は、評価したアイテム(pos_item) > 評価していないアイテム(neg_item)となるという仮定を置いて、 p(pos_item > neg_item) となる確率が最大化するようにします。
以下の式変形のように、理想的な並び順を出力する確率が最も高いモデルパラメータを算出するため、 pos_item > neg_itemとなる確率の積和が最大になるようにします。
 (i: pos_item, j: neg_item, Ds: u,i,jの組み合わせ, x_uij: p(i) - p(j) )
(i: pos_item, j: neg_item, Ds: u,i,jの組み合わせ, x_uij: p(i) - p(j) )
詳しくは下記リンクを参考にしてください。
実装の解説
次に比較実験で実装したコードを解説します。実装はhttps://github.com/EthanRosenthal/torchmf を元に、pytorch-lightningで学習し、wandbで結果の記録をするように書き換えています。
main.py
python main.py の run() にて実装された実験が開始されます。
def run(): train_data, test_data = utils.get_movielens_train_test_split(implicit=True) params = Params(batch_size=1024, num_workers=0, n_epochs=5) mf_module = train( train_data, test_data, model=MFModule, datasets_cls=Interactions, loss=nn.MSELoss(reduction="sum"), params=params, ) bpr_module = train( train_data, test_data, model=BPRModule, datasets_cls=PairwiseInteractions, loss=bpr_loss, params=params, ) print(evaluate(mf_module.model, test_data.tocsr())) print(evaluate(bpr_module.model, test_data.tocsr()))
dataset
今回はmovie lens-100kを2値に変換し、sparce_matrix形式にしたものを実験で使います。( case score > 4 then 1 else 0 )
def get_movielens_train_test_split(implicit=False): interactions = get_movielens_interactions() if implicit: interactions = (interactions >= 4).astype(np.float32) train, test = train_test_split(interactions) train = sp.coo_matrix(train) test = sp.coo_matrix(test) return train, test
MF用のDataset classの実装は以下の通りです。
class Interactions(data.Dataset): """ Hold data in the form of an interactions matrix. Typical use-case is like a ratings matrix: - Users are the rows - Items are the columns - Elements of the matrix are the ratings given by a user for an item. """ def __init__(self, mat: sp.coo_matrix): self.mat = mat.astype(np.float32).tocoo() self.mat_csr = self.mat.tocsr() self.n_users = self.mat.shape[0] self.n_items = self.mat.shape[1] def __getitem__(self, index: int) -> Tuple[Tuple[int, int], int]: row = self.mat.row[index] col = self.mat.col[index] val = self.mat.data[index] return (row, col), val
BPR用のDataset classの実装は以下の通りです。
class PairwiseInteractions(data.Dataset): """ Sample data from an interactions matrix in a pairwise fashion. The row is treated as the main dimension, and the columns are sampled pairwise. """ def __init__(self, mat: sp.coo_matrix): self.mat = mat.astype(np.float32).tocoo() self.n_users = self.mat.shape[0] self.n_items = self.mat.shape[1] self.mat_csr = self.mat.tocsr() if not self.mat_csr.has_sorted_indices: self.mat_csr.sort_indices() def __getitem__(self, index) -> Tuple[Tuple[int, Tuple[int, int]], int]: row = self.mat.row[index] found = False while not found: neg_col = np.random.randint(self.n_items) if self.not_rated(row, neg_col, self.mat_csr.indptr, self.mat_csr.indices): found = True pos_col = self.mat.col[index] val = self.mat.data[index] return (row, (pos_col, neg_col)), val
同じデータセットを利用しますが、出力形式を変えることでそれぞれの学習スキーマに対応します。
models
次にモデルの実装を解説します。
MFmodule
class MFModule(nn.Module): """ Base module for explicit matrix factorization. """ def __init__( self, n_users: int, n_items: int, n_factors: int = 40, dropout_p: float = 0, sparse: bool = False, ): super().__init__() self.n_users = n_users self.n_items = n_items self.n_factors = n_factors self.user_biases = nn.Embedding(n_users, 1, sparse=sparse) self.item_biases = nn.Embedding(n_items, 1, sparse=sparse) self.user_embeddings = nn.Embedding(n_users, n_factors, sparse=sparse) self.item_embeddings = nn.Embedding(n_items, n_factors, sparse=sparse) self.dropout_p = dropout_p self.dropout = nn.Dropout(p=self.dropout_p) self.sparse = sparse def forward(self, users: np.ndarray, items: np.ndarray) -> np.ndarray: ues = self.user_embeddings(users) uis = self.item_embeddings(items) preds = self.user_biases(users) preds += self.item_biases(items) preds += (self.dropout(ues) * self.dropout(uis)).sum(dim=1, keepdim=True)
nn.Embeddingを使って、batchで入力されるusers, itemsそれぞれの表現ベクトルの積を算出します。この実装ではSimonさんが考案したMFのように、正例だけで最適化できていないので注意してください。
元実装ではdropoutを挟んでいたため、自分の実装でも利用しています。余談ですが、MFにおけるdropoutの理論・特性はこの論文にまとまっていました。気になる方は読んでみてください。
BPR module
class BPRModule(nn.Module): def __init__( self, n_users: int, n_items: int, n_factors: int = 40, dropout_p: float = 0, sparse: bool = False, model=MFModule, ): super().__init__() self.n_users = n_users self.n_items = n_items self.n_factors = n_factors self.dropout_p = dropout_p self.sparse = sparse self.pred_model = model( self.n_users, self.n_items, n_factors=n_factors, dropout_p=dropout_p, sparse=sparse, ) def forward(self, users: np.ndarray, items: np.ndarray) -> np.ndarray: # assert isinstance(items, tuple), "Must pass in items as (pos_items, neg_items)" # Unpack (pos_items, neg_items) = items pos_preds = self.pred_model(users, pos_items) neg_preds = self.pred_model(users, neg_items) return pos_preds - neg_preds
pl_module
学習サイクルは、pytorch-lightningのLightningModuleで定義します。(data_loader → model → lossと値渡しているだけ)。各エポック終了時に、評価値を算出したかったのですが、sparse matrix形式で上手に計算する実装を組み立てられず、処理が遅くなってしまったのでコメントアウトしています🙈
class MFPLModule(pl.LightningModule): def __init__( self, csr_mat, n_factors=10, lr=0.02, dropout_p=0.02, weight_decay=0.1, model=MFModule, loss=bpr_loss, ): super().__init__() self.csr_mat = csr_mat self.n_users = csr_mat.shape[0] self.n_items = csr_mat.shape[1] self.n_factors = n_factors self.dropout_p = dropout_p self.lr = lr self.loss = loss self.weight_decay = weight_decay self.model = model( self.n_users, self.n_items, n_factors=self.n_factors, dropout_p=self.dropout_p, sparse=False, ) def forward(self, users: np.ndarray, pairs: np.ndarray) -> np.ndarray: return self.model(users, pairs) def training_step(self, batch, batch_idx): (users, paris), vals = batch preds = self.model(users, paris) loss = self.loss(preds, vals) self.log("train_loss", loss, prog_bar=False) return loss def validation_step(self, batch, batch_idx): (users, paris), vals = batch preds = self.model(users, paris) loss = self.loss(preds, vals) self.log("val_loss", loss, prog_bar=False) return {"users": users, "preds": preds, "loss": loss} # def validation_epoch_end(self, outputs): # TODO: batch_auc is too slow. We should use a faster metric. # aucs = [] # for output in outputs: # aucs.append(batch_auc(output["users"], self.csr_mat, self.model)) # self.log("val_roc", torch.Tensor([np.mean(aucs)]), prog_bar=True) def configure_optimizers(self): optimizer = torch.optim.Adam( self.parameters(), lr=self.lr, weight_decay=self.weight_decay ) return optimizer
結果
結果は以下の通りです。

BPRの方がMRR,Precisionどちらも高い値になっていることが確認できました。
ただ、今回の実験では、本来Explicit feedback用のアルゴリズムであるMFに対して、評価値を2値に変換し、0,1どちらも重み付けせず入力しているなど不利な条件の比較になっています。
今後、より実験条件を揃えた比較などもやっていきたいです。
次やりたいこと
今回は簡単に実装と評価を行いましたが、まだまだ実運用できるレベルではないと感じています。余力があれば、以下を改善して、またブログにしたいと思います...!
- MFの実装を改良したい
- 正例だけで最適化する
- 二値分類に向いたアルゴリズムがあるのか調べ、実装する
- もっと細かく評価したい
- diversity, serendipityなどの指標を見てみる
- item, userのembeddingを可視化する
- valid_epoch_endでmetricsを測る
- 今は全ユーザ x アイテムに対して推論する必要があるので高速化が必要
- 大型のデータセットで動かしたい
- GPU対応にする
- sparce_matrix形式を保ったまま、評価値・行列計算をする
- 今回の実装では、疎行列を高速に扱うために sparce_matrix形式(
scipy.sparse.matrix) を利用していますが、評価値を計算など一部対応できていない
おわり
実装して、ブログにしようとすると意外とわからないことがいっぱい出てきました。
- MFにdropoutって使うのか?
- Adamで最適化していいのか?
- sparse_matrix形式を保って、pytorchに値を渡すにはどうしたら良いのか?
これらの疑問はそもそも、読んでるだけでは思いつかないものなので、実装して理解が深まったと思います💪
本や論文を読んでなんとなく理解した気になっていたのですが、実装して、運用可能な精度に持っていくのは思ったより難しく、いかに普段の理解が浅いかということを痛感させられました。今後論文を読むときは、ブログで説明できるくらい理解できたか?と意識したいです💪
最後まで読んでいただきありがとうございました〜
【個人開発】Railsで近くのラーメンを1タップで探せるiOSアプリ「ちかめん」のAPIを作った話
まえがき
近くのラーメンを1タップで探せるiOSアプリ「ちかめん」を作っています💪
まだまだ友人:iOS, 自分:バックエンドと2人で協力して制作中ですが
一旦、本記事では自分の担当であるバックエンド側のAPI開発備忘録を紹介します。
個人開発をしてみたいと思っている方の参考になればと思います!
想定している読者
- プログラミングはやったことあるけどWeb開発はやったことない人
- これからWebアプリケーション作成に挑戦してみたい人
どんなAPIか
下記のようにデータを返します(Gifクリックで拡大します)
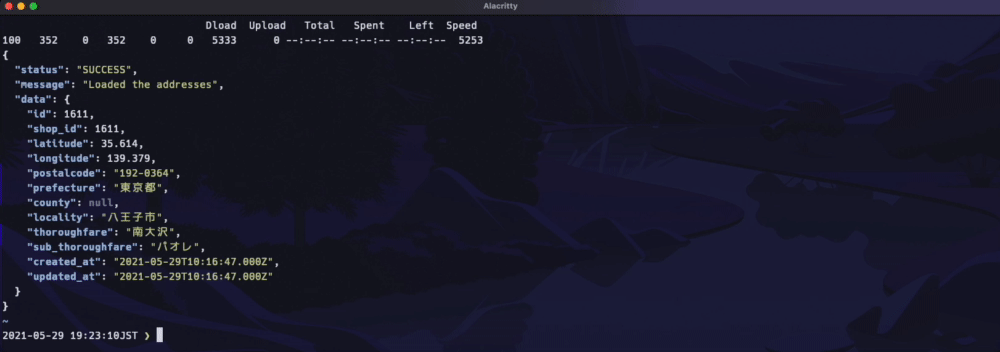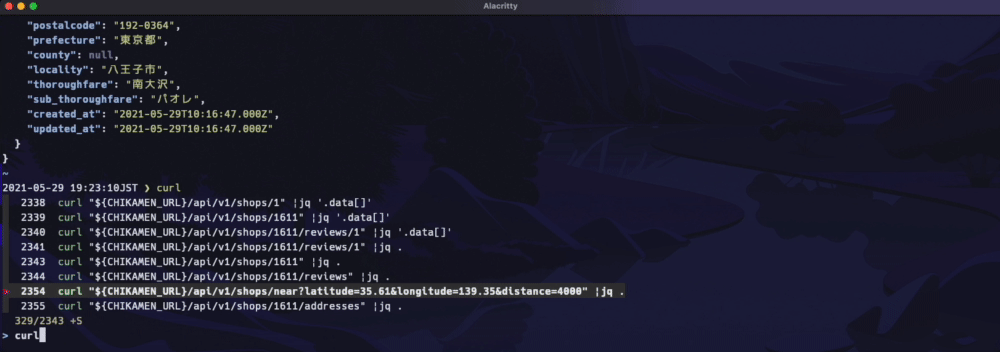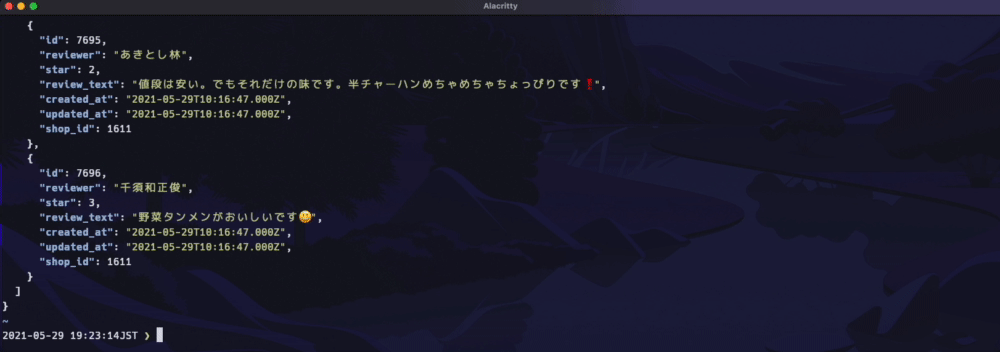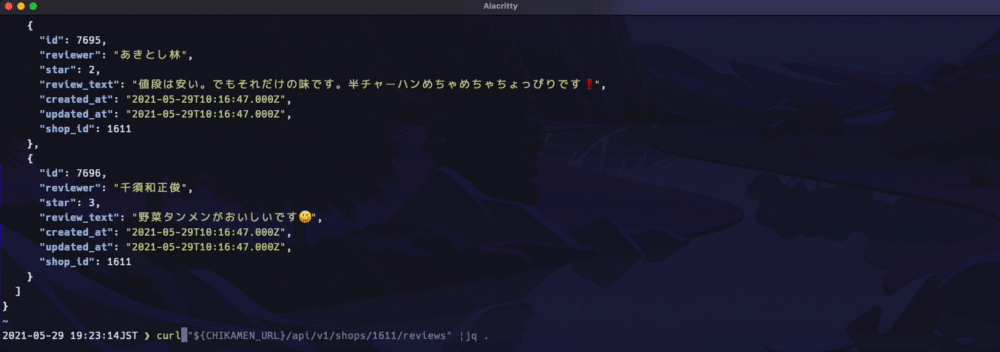
URLは下記のような構成になっています。
Prefix Verb URI Pattern Controller#Action
api_v1_shops_near GET /api/v1/shops/near(.:format) api/v1/shops#sort_by_near
api_v1_shop_reviews GET /api/v1/shops/:shop_id/reviews(.:format) api/v1/reviews#index
POST /api/v1/shops/:shop_id/reviews(.:format) api/v1/reviews#create
api_v1_shop_review GET /api/v1/shops/:shop_id/reviews/:id(.:format) api/v1/reviews#show
PATCH /api/v1/shops/:shop_id/reviews/:id(.:format) api/v1/reviews#update
PUT /api/v1/shops/:shop_id/reviews/:id(.:format) api/v1/reviews#update
DELETE /api/v1/shops/:shop_id/reviews/:id(.:format) api/v1/reviews#destroy
api_v1_shop_addresses GET /api/v1/shops/:shop_id/addresses(.:format) api/v1/addresses#index
POST /api/v1/shops/:shop_id/addresses(.:format) api/v1/addresses#create
api_v1_shop_address GET /api/v1/shops/:shop_id/addresses/:id(.:format) api/v1/addresses#show
PATCH /api/v1/shops/:shop_id/addresses/:id(.:format) api/v1/addresses#update
PUT /api/v1/shops/:shop_id/addresses/:id(.:format) api/v1/addresses#update
DELETE /api/v1/shops/:shop_id/addresses/:id(.:format) api/v1/addresses#destroy
api_v1_shop_photos GET /api/v1/shops/:shop_id/photos(.:format) api/v1/photos#index
POST /api/v1/shops/:shop_id/photos(.:format) api/v1/photos#create
api_v1_shop_photo GET /api/v1/shops/:shop_id/photos/:id(.:format) api/v1/photos#show
PATCH /api/v1/shops/:shop_id/photos/:id(.:format) api/v1/photos#update
PUT /api/v1/shops/:shop_id/photos/:id(.:format) api/v1/photos#update
DELETE /api/v1/shops/:shop_id/photos/:id(.:format) api/v1/photos#destroy
api_v1_shops GET /api/v1/shops(.:format) api/v1/shops#index
POST /api/v1/shops(.:format) api/v1/shops#create
api_v1_shop GET /api/v1/shops/:id(.:format) api/v1/shops#show
PATCH /api/v1/shops/:id(.:format) api/v1/shops#update
PUT /api/v1/shops/:id(.:format) api/v1/shops#update
DELETE /api/v1/shops/:id(.:format) api/v1/shops#destroy
主なURLと機能はこんな感じです
- 緯度経度を入力すると近くのラーメンデータをDBに保存して返す
nearURL nearで保存したリソースを返すshop,reviews,photos,addressesURL- 過去にアクセスされた緯度経度を保存し、再び近隣でアクセスした場合はDBからキャッシュを返す
データ取得はGoogle Map APIから行っています。
このAPIは月々2万円分は無料で使用できるため、必要なデータだけ取得し、
再度必要になる場合は保存したデータから返すような機構にして、リクエスト数を抑えています。
なんで作ったか
RailsやWebアプリケーションの基礎を身につけ、社内でのコミニュケーションを取りやすくするためです。
自分はWeb企業にデータサイエンティストとして入社したのですが、Webアプリの基礎知識がないと、
MLモデル導入のインタフェースなど業務上で齟齬が生まれると感じたからです。
また、社内の勉強会や雑談はWebの知識を前提としていることが多く、そこで話が通じるようになりたいと思っていました。
具体的には下記のような知識を得られると思い作成しました。
- RailsなどのWebフレームワークの使い方
- Webアプリケーション開発の全体像
- GCP, AWSなどのクラウドの使い方
- チーム開発におけるコミニュケーション方法(Pull Request, issueの作り方等)
どんな実装になってるか
(雑ですが)全体像を示します。

サーバーをAWSにアップロードしており、URLにアクセスすると必要に応じてGCPまたはDBからデータを取得するようになっています。
DBには下記のような構成でデータが格納されており、上に載せたようなURLでアクセスできます。

必要なデータはGoogle MAP APIから取得して、これをDBに整形してから格納しています。
このAPIは月2万円分までは無料で使えるため、その限度を超えないようにデータを保存しています。
サーバーの構成などは殆ど下記のURLを参考に作成しました。
作成の流れ
2020/11/10から作成しはじめました。
自分達と友人が使えるアプリがいいねということで、何個か案をだし、つくば市(当時住んでいた)のラーメンを探せるアプリ「つくめん」を作ることにしました。
最初にAPIのURL設計とデータの形式を決め、モックを作ってそれぞれ個別に作業を進めました。
お互い引っ越すタイミングで、「来年つくばにいなくない?」ということに気付き、現在地から近辺のデータを取得する「ちかめん」に変更しました。
実働は30~50時間くらいで、コミットログからどの時期にどれくらい作業していたかがわかります。

一通り実装が終わったので友人に共有したところ、データが意図しない型、重複、nullになっていたりと穴だらけだったので、
一旦はもっとシンプルな「つくめん」としてアプリをリリースしようと現在作業を進めています。
ちかめんのリリースは少し時間がかかりそうなので、今までやったことを忘れないようにブログを書いた次第です。
どうやって知識をキャッチアップしたか
Railsは日本語で無料の良質な情報がWeb上にたくさんあるので、知りたい情報がなくて困ることはなかったです。
という感じで進めました。
自分のような初心者の方がコードを書く場合、良質な教材がある・気軽に聞ける人がいる言語で書き始めるとよいのかなーと思いました。
得られた知識
得られた知識はこんな感じです。
また、自分がバックエンドエンジニアとして働くには以下の事を更に勉強する必要がありそうだと実感できました。
- 複雑性を避ける設計
- DB・サーバー間の分離などのインフラ構成・通信
- データの信頼度の担保
- デバッグ・追加検証しやすいログの設計
得られた体験
機能追加を話すのは楽しい。実装は大変。
なんてことない機能も、実際に動くものを作るのは想像より遥かに大変でした。
飽きないように、そしてちゃんとユーザーに使ってもらえるように、届けたい価値はなにかを考えてMVPで実装することが大事だと感じました。
このあたりをちゃんと考えると実務のプロダクト開発にも活かせると思うので次作るときは、
下記の本とか参考に意識したいです。🤲
フレームワークの恩恵を得られる構成で作るとラク
RailsはActiveRecordにより、基本的なCRUD機能やルーティングを少量のコードで実装することが出来ます。
フレームワークの特性を知り、自分たちが提供したいアプリの機能をそこにマッピングしていくとコスパよく実装できると感じました。
リリースできる品質にするのは難しい
GCPからデータを取ってきてDBに入れるだけでも、データの重複、欠損値などをvalidateするのに苦労しました。
またデプロイ時には開発環境の差異で落ちたり、ネットワークの知識が足りずポートが開いていなかったりといろいろ大変でした汗
事業に成り立たせるにはサービスを落とさないようにしたり、大量のデータをさばいたりと更に考えることがいっぱいなのだなと実感し、世の中のエンジニアに敬意を払いたいと思いました...笑
お世話になったサイト・書籍
終わり
やっぱり動くものができあがるのはすごく楽しいと感じました。
これからWeb開発をしたい!という人の参考になったらうれしいです!
アプリをリリースできたらまた記事を書きたいと思います!
では〜
2020年の振り返りと2021年の目標
こんにちは、ひぐです。
年の瀬なので、今年を振り返りたいと思います!
ということで、早速去年の目標を採点してみました。

凄惨たる結果です...
まあ振り返ることが大事だと思うのでやっていきます。。
できたこと
研究した
学部からテーマを変えた上に、去年はかなり就活に時間を振ってたので
今年は頑張って研究しました。
- 国際学会オーラル発表 1(研究結果引き継いでまとめただけなのですごくない)
- 国内学会オーラル発表 1
- 国際ジャーナル投稿 1 (査読中)
- 修士論文
ですが、結果を出すのがなかなか難しかったです。
ニューラルネットの研究は再現するのが大変なので大変でした()
MLエンジニアとしての基礎知識を身に着けた
来年度から社会人になるため、今年はまとまった時間を使って、
MLエンジニアに必要な基礎知識をがっつり勉強するぞ!というのがテーマでした。
興味が広範に渡ってしまったためどれも中途半端気味ですが、割と勉強できたと思います。
特に良かった本に☆をつけました
統計・数学
統計検定準1級・1級を取るために勉強しました。
友人と朝8~11時Zoomで輪講できたのが良かったです。(続けたかった)
読んだ本
プログラミング設計
インターンで設計の大切さを知った&研究コードのスパゲッティぷりに、
辟易していたので色々と読みました。
学生っぽいコードから少し脱却できたような気がします。
読んだ本
- テスト駆動開発
- Clean Code(途中)
- Clearn Architecture☆
- SQLアンチパターン
- ドメイン駆動設計開発(途中)
- レガシーコードからの脱却(途中)
- オブジェクト指向でなぜ作るのか
- 自走プログラマー
- リファクタリング 第2版(途中)
Webバックエンド
内定者インターンを4ヶ月取り組みました。
- Golang
- Elasticsearch
- Dependency Injection
- マイクロサービスアーキテクチャ
あたりを少し理解しました!
Railsを使って友達と個人開発をしているのでこれも卒業までに形にしたいです。
ビジネス
読み物としてどれも面白かったです。 日常生活で特に活かせなかったのが反省。
読んだ本
- リーンアナリティクス
- リーンスタートアップ
- ストーリーとしての競争戦略☆
自己啓発
一人で過ごしたり、課題に取り組む時間が多かったので、 セルフマネジメント的なことは以前より考える時間は増えて、できるようになった気がします。
読んだ本
- issueから始めよ
- 金持ち父さん貧乏父さん
- コンサル1年目が学ぶこと
- 独学大全☆
心身ともに健康に過ごせた
コロナで全然外に出なくなったので、友達とテニスをたくさんするようになりました。 散歩したり風呂に入ったりでストレスを無理なく調整できるようになった気がします。
#今年買ってよかったものベスト3
— ひぐ (@zerebom_3) 2020年12月19日
1. オフィスチェア ハーマンミラー セイルチェア
2. ヘッドホン ソニー WF-1000XM3
3. ロボット掃除機 Eufy RoboVac 15C Max
(4. iPhone12 mini, 5. Alfred4 有料版, 6. コーヒーメーカー, 7 Apple watch SE ...)
そのた
- vim, alfredなどを使ってPC操作力が上がった
- Notionで読んだ本をメモするようになった

ブログがホットエントリに載った
— ひぐ (@zerebom_3) 2020年12月12日
学費をちゃんと稼いだ
- テニスのバックハンド・ボレーがちょっと上達
- AtCoder茶色になった
できなかったこと
データ分析コンペ
目標Kaggle Master!と息巻いた割に、そもそもコンペに参加もせず全然だめでした。 参加コンペ数とかサブミット数とか自分で制御できる目標にするべきでした。
英語
TOEIC 850点以上は未達でした。(むしろ下がった)
英語は筋トレみたいに続けることが大事だと思うので、 スタディサプリに課金して毎日やることにしました。
登壇
コロナでイベントがないから、、、と言い訳して出ませんでした。
LT枠で参加してから考える的な思い切りの良さが大事かも。
来年の目標
社会人1年目なのでキャリアの設計が〜とか考え込みすぎず、 とりあえず興味があることにガンガン取り組んでいきたいです。
- お仕事がんばる
- 実現可能な目標を建てて有言実行する
- イベントやコンペは迷ったら参加
- (とりあえず)統計検定準1級
おわり。
Pytorch-lightning+Hydra+wandbで作るNN実験レポジトリ
Kaggle Advent Calender2020の 11日目の記事です。
昨日はhmdhmdさんのこちらの記事です! 2020年、最もお世話になった解法を紹介します - Qiita
明日はarutema47さんの記事です! (後ほどリンクはります)
本記事では、深層学習プロジェクトで使用すると便利なライブラリ、
Pytorch-lightningとHydraとwandb(Weights&Biases)について紹介したいと思います。

対象読者
- Pytorchのボイラープレートコードを減らせないか考えている
- 下記ライブラリについては聞いたことあるけど、試すのは億劫でやってない
書いてあること
- 各ライブラリの役割と簡単な使い方
- 各ライブラリを組み合わせて使う方法
- 各ライブラリのリファレンスのどこを読めばよいか、更に勉強するにはどうすればよいか
また、上記3つのライブラリを使用したレポジトリを用意しました。 ブログと一緒に見ていただくとわかりやすいかと思います! github.com
はじめに各ライブラリを個別に解説し、次に上記レポジトリに注釈を入れながら説明したいと思います。
Pytorch-lightning
概要
Pytorch-lightningはPytorchの軽量ラッパーです。 ボイラープレートコードを排除しつつ、可読性を向上させることが出来ます。
特徴(Lightning Philosophy)
公式GitHubを見ると以下の原則を念頭に置いて設計されているようです。
- 最大限の柔軟性を持てる
- ボイラープレートコードを抽象化しつつ、必要があればアクセスできる
- システムに必要なものをすべてを保持し、自己完結できる
- 以下の4要素に分割し、整理する
- 研究コード(Lightning Module)
- エンジニアリングコード(Trainer)
- 非必須の研究コード(Callback)
- データ (Pytorch DataloaderかLightningDataModule)
どのようなモデルを実装しても似たインターフェースになり、他人(≒過去の自分)のコードでもすぐに理解できる。 MultiGPUやTPUでも実装の変更が殆どないといった点が素晴らしいと思います。
Install
pip install pytorch-lightning
使い方
上記Lightning Philosophyにあるように、4つのパートについてそれぞれ説明していきます。
Trainer
Trainerは後述するLightningModule, Callbacks, DataModuleを引数にとり、Training loop を司るクラスです。いわゆる親玉。
CPU・MultiGPU・TPUなどの実行環境や、デバックモードやエポック数など、
細かい設定を引数に取ることが出来ます。
例)
# 関数にconfig(cfg)を渡すデコレータ(後述) @hydra.main(config_path='../config', config_name='pix2pix') def main(cfg): # モデルの動的呼び出し model = hydra.utils.instantiate(cfg.model.instance,hparams=hparams, cfg=cfg) dm = DataModule(cfg) dm.setup() trainer = pl.Trainer( logger = wandb_logger, checkpoint_callback=model_checkpoint, callbacks=[lr_logger,early_stopping,wandb_callback], **cfg.trainer.args, ) # 学習開始 trainer.fit(model, dm)
どのような引数を取ることができるかは下記リファレンスに記載されています。
trainer - PyTorch Lightning 1.0.8 documentation
LightningModule
参考: LightningModule - PyTorch Lightning 1.0.8 documentation
モデルの学習に関するデータフローなどを記載するクラス。
親クラスにtorch.nn.Module を継承しており、高機能な nn.Module と捉えるとわかりやすいです。
各フェーズごとにメソッドが定義されており、その中に処理を書くことで実行されます。
また、Trainerにわたすことで実行環境に応じたコードを自動で実行してくれます。
つまり、x.cuda() や x.to(device) を呼び出したり、
Dataloader に DistributedSampler(data) を渡す必要がなくなります。
生えてるメソッドの説明
forward
nn.Moduleと同じXX_step
引数batchにdataloaderの中身が格納されているので、 これをモデルに通して、誤差を計算します。 Loggerやtqdm barに渡したい値はself.logに渡すことで記録されます。XX_epoch_end
epochが終わったときにどんな処理を行うかを書きます。 epoch間のlossやmetricの平均値などを記録すると良いと思います。configure_optimizers
optimizer,schedulerの初期化をします。
例)
import os import torch from torch import nn import torch.nn.functional as F from torchvision.datasets import MNIST from torch.utils.data import DataLoader, random_split from torchvision import transforms import pytorch_lightning as pl class LitAutoEncoder(pl.LightningModule): def __init__(self): super().__init__() self.encoder = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 3)) self.decoder = nn.Sequential(nn.Linear(3, 128), nn.ReLU(), nn.Linear(128, 28 * 28)) def forward(self, x): # in lightning, forward defines the prediction/inference actions embedding = self.encoder(x) return embedding # dataloaderの返り値, indexが格納されている def training_step(self, batch, batch_idx): # training_step defined the train loop. It is independent of forward x, y = batch x = x.view(x.size(0), -1) z = self.encoder(x) x_hat = self.decoder(z) loss = F.mse_loss(x_hat, x) # 追跡したい値はself.log取ることができる self.log('train_loss', loss) return loss def configure_optimizers(self): optimizer = torch.optim.Adam(self.parameters(), lr=1e-3) return optimizer
Callbacks
参考:Lightning in 2 steps - PyTorch Lightning 1.0.8 documentation
学習に非必須な処理を書くクラス。
Logger , EarlyStopping LearningRateScheduler など。
一般的によく使われる処理はすでに用意されています。
自分で書く場合は、LightningModuleと同じメソッドが生えているので、
各フェーズで何をするかを書きます。
こちらもTrainerに引数として渡します。
例)
class DecayLearningRate(pl.Callback) def __init__(self): self.old_lrs = [] def on_train_start(self, trainer, pl_module): # track the initial learning rates for opt_idx in optimizer in enumerate(trainer.optimizers): group = [] for param_group in optimizer.param_groups: group.append(param_group['lr']) self.old_lrs.append(group) def on_train_epoch_end(self, trainer, pl_module, outputs): for opt_idx in optimizer in enumerate(trainer.optimizers): old_lr_group = self.old_lrs[opt_idx] new_lr_group = [] for p_idx, param_group in enumerate(optimizer.param_groups): old_lr = old_lr_group[p_idx] new_lr = old_lr * 0.98 new_lr_group.append(new_lr) param_group['lr'] = new_lr self.old_lrs[opt_idx] = new_lr_group
DataModule
データにまつわる全てのコードを集約するためのクラスです。
DatasetとDataLoaderの呼び出しをします。
(Pytorch-lightning 1.0以前はデータにまつわる処理も LightningModule に書く必要がありました。)
例)
class MyDataModule(LightningDataModule): def __init__(self): super().__init__() def prepare_data(self): # download, split, etc... # only called on 1 GPU/TPU in distributed def setup(self): # make assignments here (val/train/test split) # called on every process in DDP def train_dataloader(self): train_split = Dataset(...) return DataLoader(train_split) def val_dataloader(self): val_split = Dataset(...) return DataLoader(val_split) def test_dataloader(self): test_split = Dataset(...) return DataLoader(test_split)
pytorch-lightning.readthedocs.io
Hydra
概要
Facebook Open Sourceから公開されている設定管理ツールです。 YAMLやDataclassから設定変数を階層構造をもたせて動的に呼び出すことができます。
特徴
- 複数のソースから階層的に設定を構築できる
- コマンドラインから設定の指定や上書きが可能
- 1つのコマンドで複数のジョブを実行できる
Install
pip install hydra-core --upgrade
使い方
最小限の使い方
configファイルにyaml形式で設定を書きます。
# config.yaml db: driver: mysql user: omry pass: secret
参考:YAML Syntax - Ansible Documentation
設定を呼び出す側には呼び出したい関数に @hydra.main デコレータを渡します。
各要素にはドットノーテーションでアクセスできます。
# main.py @hydra.main(config_path="./config",config_name="config") def my_app(cfg : DictConfig) -> None: print(cfg) print(cfg.db.driver)
Config の構造化
configディレクトリを階層構造にすることで、configも階層構造でもたせる事が可能になります。 例えば、以下のようにディレクトリを構築します。
config
├── config.yaml
├── data
│ ├── cifar10.yaml
│ └── mnist.yaml
└── model
├── resnet_18.yaml
└── resnet_50.yaml
そしてrootとなる config.yaml を下記のように記載すると、
data, modelそれぞれ指定したyamlファイルを読み込んでくれます。
# config.yaml
defaults:
- data: cifar10
- model: resnet_18
呼び出される側の設定ファイルの1行目に # @package _group_ と記載すると、
そのディレクトリ名経由でドットノーテーションアクセスできます。
# @package _group_ shape: [1,28,28] batch_size: 8
を ./config/data/default_data.yaml に書いたなら、cfg.data.shape とアクセスできます。
非常に便利な機能ですが、どの単位でフォルダを分割するかが結構難しいです...!
良いアイディアがあったら教えてほしいです🙇
コマンドラインでの上書き
コマンドライン引数にわたすことで呼び出すファイルや設定を上書きできます。
# 設定ファイルの入れ替え
python train.py data=cifar10
# 値の変更 python train.py trainer.min_epoch=100
インスタンスの動的呼び出し
参考: Instantiating objects with Hydra | Hydra
Hydraの強力な機能にオブジェクトの動的呼び出しがあります。
_target_ に呼び出したいオブジェクトを指定し、引数を列挙することで動的に呼び出すことが出来ます。
# ./config/callbacks/default_callbacks.yaml # @package _group_ EarlyStopping: # 呼び出したいオブジェクト名 _target_: pytorch_lightning.callbacks.EarlyStopping # 第2要素以降はオブジェクトの引数 monitor: ${trainer.metric} mode: ${trainer.mode}
# 呼び出し側。コード内のローカル変数を引数にしたい場合はキーワード引数で渡す。
model_checkpoint = instantiate(cfg.callbacks.ModelCheckpoint,patience=patience)
ユニットテストやnotebookで呼び出す方法
initialize_config_dir メソッドを使うことで呼び出すことが出来ます。
from hydra.experimental import initialize_config_dir, compose with initialize_config_dir(config_dir=config_dir): cfg = compose(config_name=config_name)
Wandb
概要
Wandbは機械学習プロジェクトの実験のトラッキング、ハイパーパラメータの最適化、
モデルやデータのバージョンニングを行うライブラリです。
install・会員登録
pip install wandb
公式サイトの右上のLoginリンクからsign upすれば使えます。
GithubかGoogleアカウントを連携すればOKです。
Weights & Biases - Developer tools for ML
特徴
大きく分けて下記の機能があるようです。 (自分はまだDashboardくらいしか使っておりません🙇)
- Dashboard: 数行のコード追加で実験logを記録
- Sweeps: 複数の条件のモデルを一度に実行
- Artifacts: モデルやデータなどをバージョンニングフォルダのように管理
- Reports: 自分の実験を他者に見やすく公開
複数のPCの実験結果をWebブラウザから一括で見られるのは非常に便利だと感じました。
使い方
最小限の使い方
主にPytorch-lightningで使用する方法について説明します。
参考: PyTorch LightningとWandbの連動方法
使い方は非常に簡単で、 pytorch_lightning.loggers.WandbLogger を呼び出して、Trainer に渡すだけです。
tagsやnameを指定すると、project内の実験をソートしたり条件を絞るのに便利。
from pytorch_lightning.loggers import WandbLogger wandb_logger = WandbLogger( name="ResNet18-cifar10", project=”ImageCrassfication”, tags=["ResNet18","cifar10"]) trainer = pl.Trainer(logger=wandb_logger,**trainer.args)
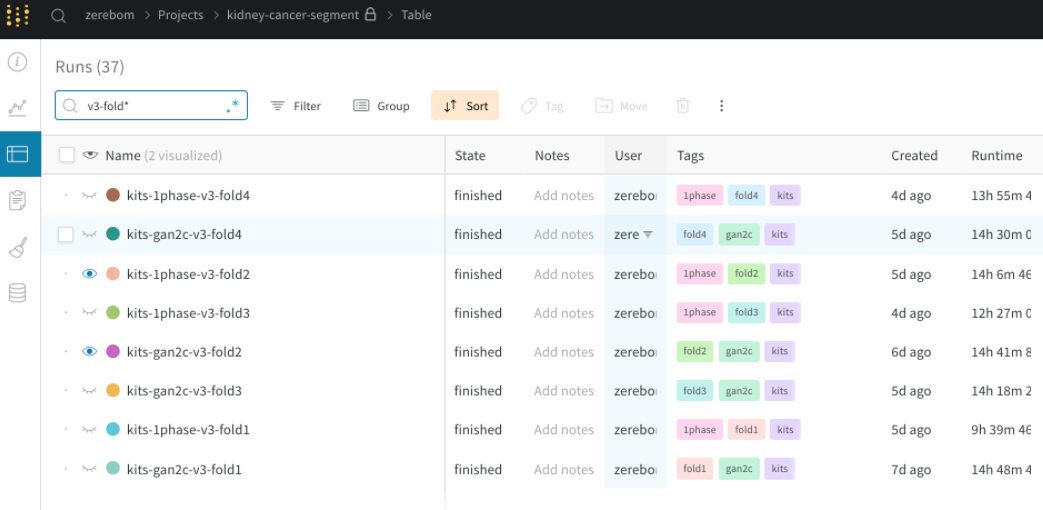
Traceしたい値は、LightningModuleで self.log に指定するだけで自動で追加してくれます。
def training_step(self, batch, batch_idx): loss, k_dice, c_dice = self.calc_loss_and_dice(batch) self.log("k_dice", k_dice) self.log("c_dice", c_dice) return loss
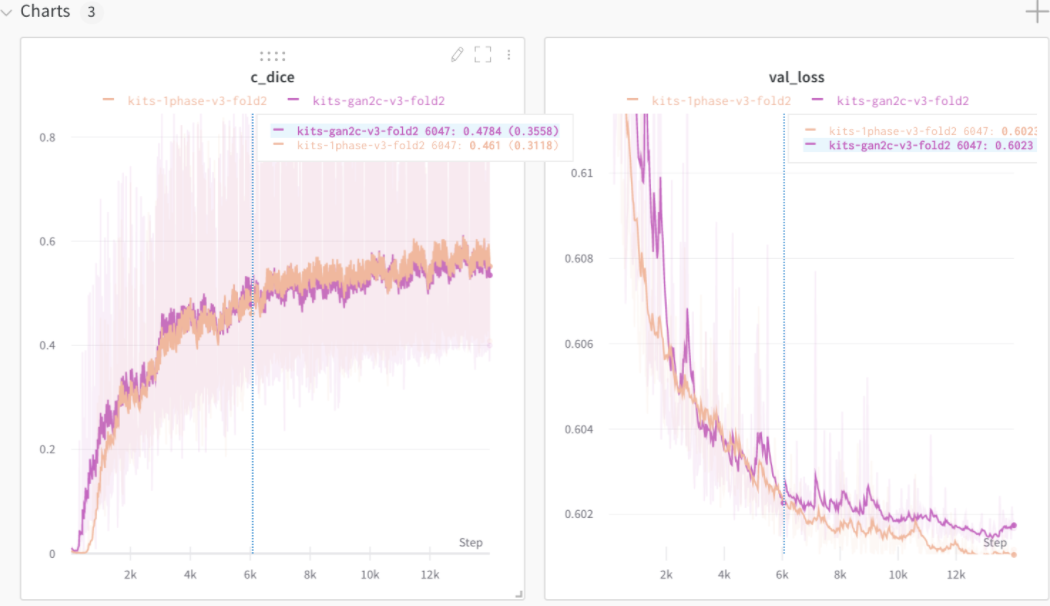
さらに、 watch メソッドを呼ぶだけで、モデルの重みの分布を記録してくれます。
wandb_logger.watch(model, log='gradients', log_freq=100)

画像の出力
GANのGeneratorの生成結果や、Segmentの結果などを出力する機能もあります。
Pytorch-lightningで使用するには Callback を書き、Trainerに渡すことで保存できます。
class ImageSegmentationLogger(Callback): def __init__(self, val_samples, num_samples=8,log_interval=5): super().__init__() self.num_samples = num_samples self.val_imgs, self.val_labels = val_samples self.log_interval = log_interval def on_validation_epoch_end(self, trainer, pl_module): # Bring the tensors to CPU val_imgs = self.val_imgs.to(device=pl_module.device) val_labels = self.val_labels.to(device=pl_module.device) #[B,C,Z,Y,X] pred_probs = pl_module(val_imgs) #[B,Z,Y,X] -> [B,Y,X] preds = torch.argmax(pred_probs, 1)[:,0,...].cpu().numpy() val_labels =torch.argmax(val_labels, 1) [:,0,...].cpu().numpy() class_labels = { 0: "gd", 1: "kidney", 2: "cancer", 3: "cyst" } # Log the images as wandb Image trainer.logger.experiment.log({ "examples": [wandb.Image(x, masks={ "predictions": { "mask_data": pred, "class_labels": class_labels }, "groud_truth": { "mask_data": y, "class_labels": class_labels } }) for x, pred, y in zip(val_imgs[:self.num_samples], preds[:self.num_samples], val_labels[:self.num_samples])] })
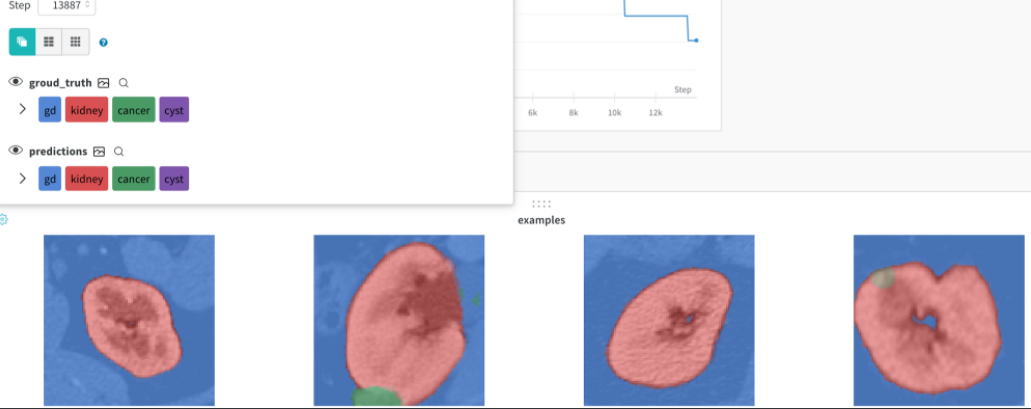
サンプルレポジトリの解説
GitHub - zerebom/hydra-pl-wandb-sample-project
config dir
実験パラメータは ./config/default_config.yamlを通して渡されます。
├── config │ ├── callbacks │ │ └── default_callbacks.yaml │ ├── data │ │ └── default_data.yaml │ ├── default_config.yaml │ ├── env │ │ └── default_env.yaml │ ├── logger │ │ └── wandb_logger.yaml │ ├── model │ │ └── autoencoder.yaml │ └── trainer │ └── default_trainer.yaml
train.py
実行する train.py は基本的にpl.Trainerの組み立てだけ行います。
@hydra.main(config_path='../config', config_name='default_config') def train(cfg: DictConfig) -> None: model = instantiate(cfg.model.instance,cfg=cfg) dm = DataModule(cfg.data) dm.setup() wandb_logger = instantiate(cfg.logger) wandb_logger.watch(model, log='gradients', log_freq=100) early_stopping = instantiate(cfg.callbacks.EarlyStopping) model_checkpoint = instantiate(cfg.callbacks.ModelCheckpoint) wandb_image_logger = instantiate(cfg.callbacks.WandbImageLogger, val_imgs=next(iter(dm.val_dataloader()))[0]) trainer = pl.Trainer( logger = wandb_logger, checkpoint_callback = model_checkpoint, callbacks=[early_stopping,wandb_image_logger], **cfg.trainer.args, ) trainer.fit(model, dm)
それぞれのパーツは ./src/factory dirに入っています。
└── src
├── factory
│ ├── dataset.py
│ ├── logger.py
│ └── networks
│ └── autoencoder.py
output dir
poetry run python train.py を実行すると、output dirが作成されます。
ここに重みやlogが格納されます。
output
└── sample-project
└── simple-auto-encoder-1
output dir の出力先は default_config.yaml で設定できます。
hydra:
run:
dir: ${env.save_dir}
# env.save_dir: ${env.root_dir}/output/${project}/${name}-${version}
おわりに
ここまで読んでいただきありがとうございます!
(スコープを広げすぎてとっ散らかってしまった気がする...)
実験管理ディレクトリの作成はなかなか奥が深く、人によって個性が出ると思います。
exp dirを作って1実験1ファイルで管理する方法も人気が高いみたいですね。今度そのような方法にも挑戦してみたいです。
今後、もっと複雑なGANモデルを実装して公開したいと思ってます。
(このGANを書き直す予定)
lucidrains/lightweight-gan
参考文献
レポジトリ
wandb+Hydraを使用したKaggle solution
非常に参考にさせていただきました🙇
shimacos37/kaggle-trends-3rd-place-solutionpytorch-lightning公式 Template
PyTorchLightning/deep-learning-project-template
Pytorch-lightning
pytorch-lightningでCycleGAN実装例
GANはLightningModuleにモデルが2つ以上必要になるので、ちょっと書き方にコツが要ります。
CycleGAN - Pytorch LightningPytorch-lightning 日本語解説
PyTorch Lightning入門から実践まで -自前データセットで学習し画像分類モデルを生成-
Hydra
Hydra + Mlflow
ハイパラ管理のすすめ -ハイパーパラメータをHydra+MLflowで管理しよう- - やむやむもやむなしHydra + Ax
Hydraでハイパーパラメータのサーチができるそうです
【Zoom or Die】第2回 Hydra+Axでハイパーパラメータサーチ - Sansan Builders Blog
Wandb
wandb Gallery
WandbのReport機能を使って公開された実験のギャラリー
The Gallery by Weights & Biasespytorch-lightning with wandb
上のGalleryの中でPytorch-lightningを一緒に使っているライブラリ
PyTorch Lightning