本記事はWantedly 21新卒 Advent Calendar 2021の22(???)日目の記事です!(今は2021年12月22日 午後220時です。)
最近、From RankNet to LambdaRank to LambdaMART: An Overview というサーベイ論文を読みました。本記事ではその論文をもとに、ランキング学習のアルゴリズムである、RankNet, LambdaRankの解説をしたいと思います。
なるべく数式を噛み砕いて説明しようと思いますが、久しぶりにちゃんと数式を追ったので、間違っている部分もあるかもしれないです...悪しからず...(数式はサーベイ論文から引用しています。)
ランキングモデル・ランキング学習とは?
ランキングモデルとは、アイテムの集合を、定義した重要度順にソートして返すモデルのことを指します。このモデルを機械学習を使って構築すること、そのスキームを、ランキング学習(Learnig To Rank, LTR)と呼びます。
ランキングモデルは入力に、何ついて情報を得たいか指定する”クエリ”とアイテムの特徴量を受け取り、重要度順にソートされたアイテム群や、アイテム群の重要度のスコアを出力します。LTRの文脈では各アイテムのことを文書(docment)と呼ぶことが多いです。

RankNetとは
RankNetはデータセット内のクエリが同じアイテムをランダムに2つ選び、そのペアの順序関係が正しくなるように学習を進める、Pairwiseランキング学習の手法の一つです。
RankNetのベースモデルは、アイテムの特徴ベクトルを入力に、重要度のスコアを出力します。
このベースモデルから得られる、二つのアイテムSi, Sj のスコア差をsigmoid関数に通すことで、アイテム Si > Sjとなる確率を求めます。
そして、この Si > Sjとなる確率と理想的な並びになるとき得られる真の確率に近づけるように学習をします。
真の確率との誤差はクロスエントロピーで計算します。

理想の確率は以下の通りです。
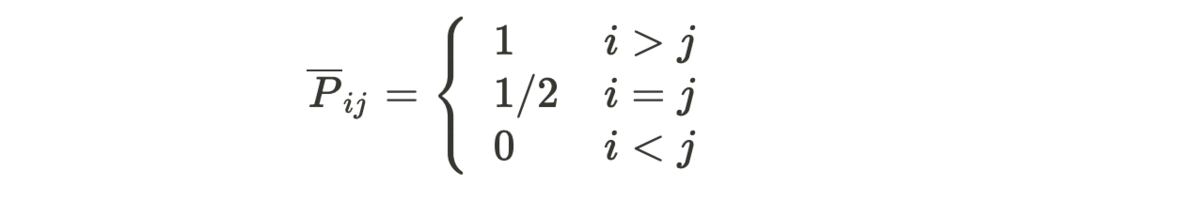
モデルパラメータwの更新に必要な損失Cの微分は以下のようになります。
数式メモ
- wがi, jの合成関数なので、項が二つに別れる
なので、不等号を入れ替えて項をまとめている
このλは、アイテムiがアイテムjから受ける勾配として捉えることができます。
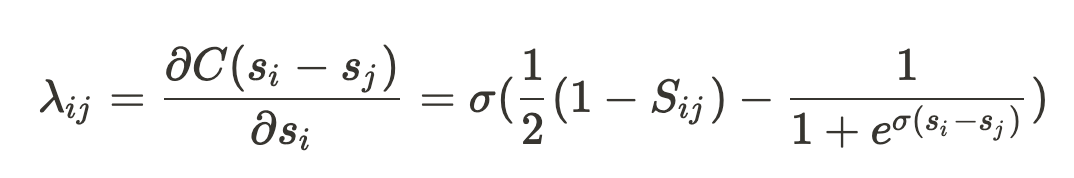
数式メモ
だと値は0に、
だと -2σに近づく
- 順序関係が誤っている場合は、負の方向にスコアが更新される
LambdaRankとは
LambdaRankは以下のようなRankNetの課題を解決するために改良したランキングモデルです。
- RankNetが行うのは、あくまでペア同士の順序関係の最適化なので、アイテムの位置によって損失への重みを変えることができない
- 一般的にランキングは上位アイテムの並び順に強い重みをつけたほうが良い
- nDCGやMRRなどランキングの評価指標も上位アイテムの並び順に強い重みをつけている
- 1回のモデルの更新のために、全アイテムの組み合わせのスコア差が必要で、計算量が多い
- 例えばiの勾配を得るには、i以外全てのアイテムとのスコア差を算出する必要がある。
上記の問題を解決するために、LambdaRankは勾配として利用するλを以下のように定義します。
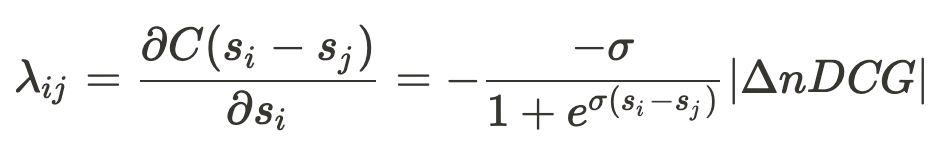
この はi, jを入れ替えた時のnDCGの差分で、またnDCGに限らず、任意のランキングの評価指標に置き換えて学習することもできます。
なぜ置き換えが成立するのかというと、アイテムを入れ替えた時のランキングの評価指標の差分もRankNetの の項と同様に、スコアの出力が真の確率から遠いほど、大きな負の値をとるという性質を持っているからと、解釈しています。
この置き換えを行うことで、モデルを1回更新するのに、必要な計算量が減り、また任意の評価関数を可能になります。つまりRankNetの課題を解決することができます。
おわりに
久しぶりに数式をちゃんと追って論文を読みました。めちゃくちゃ時間かかるけど、さっと読んでもすぐ忘れてしまうので、たまにはじっくり読むの良いなと思いました💪 サーベイ論文で紹介されていたLambdaMARTについても、いつかちゃんと読み込んでブログに足していきたいです...!(一応読んだけど、人に説明できるほど理解できなかったorz)
余談ですが、Wantedly 21新卒 Advent Calendar 2021 を無事走破できました!🎉 他の記事も良ければ読んでみてください!
zerebom.hatenablog.com www.wantedly.com zerebom.hatenablog.com zerebom.hatenablog.com
参考文献
ランキング学習の概要 jp.kamulau.com
RankNetの実装 www.szdrblog.info
RankNetの実装 qiita.com
RankNetの解説 ryo59.github.io
LambdaNetの解説 jp.kamulau.com
LambdaMartの解説 jp.kamulau.com